
IlPadrino
Well-known member
Could you post the similar problem?I looked a similar problem in Traffic Engineering text book by Roess, Prassas and McShane pg. 210
Could you post the similar problem?I looked a similar problem in Traffic Engineering text book by Roess, Prassas and McShane pg. 210
Here is where we disagree clearly, and I invite you to find any definition of percentile which supports your belief.when solving the problem, the 85th percentile should not be confused with the 85th vehicle.
for some reason I am not able to upload any more files. If you can give me your email address I would be happy to email it to you.Could you post the similar problem?I looked a similar problem in Traffic Engineering text book by Roess, Prassas and McShane pg. 210



Yes, we are. A histogram is a way or representing the distribution of data by their frequency.Also, we're not talking about histograms, we're talking about percentiles based on average speed.
Not so... even if all 24 vehicles were traveling at 40 mph, the 85th vehicle is still in the 45-49 bin. Really, this is the point of our disagreement, so it would go a long way towards resolution if you could explain why you think the 85th vehicle (after arranging the observed speeds from slowest to fastest) could be anywhere in the 40-44 bin. Would you please address just this difference in our perspectives?Also, no one can assume the specific speeds of the vehicles, so for all we know, all 24 cars in the 40-44 mph category could have been travelling at 40 miles per hour. If this is the case (i.e. based on actual speeds), then the 85th percentile is 41 mph.

")
MH. I totally see what you are saying. And, yes, if you were to simply take the 85th fastest car using my averaging suggestion, that car would be going 47mph. But (and maybe I am looking at this incorrectly) that's not my understanding of how the 85th percentile is established. I was taught to use the formula I showed in my post #32 above.Major Highway said:But it still isn't correct. Okay, let's do the old excel trick on the assumption that every vehicle in each bin is traveling at the average speed for that bin. In that case the 85th percentile is 47 mph. Do it, go ahead, test your hypothesis.This, of course, only works if you can make the assumption that, for example, all 18 cars traveling in the 30-34mph interval were traveling at 32mph. Which they probably weren't but, without additional data, I think this is a valid assumption. For all we know, all 18 cars could have been traveling at 30mph, all at 34mph, etc.
OK... I think I understand where your confusion lies. The procedure you've given (linear interpolation) is used to establish the percentile when there is not enough data (i.e. observations) such that one of the speeds is not exactly equal to the percentile of interest. Take a look at http://en.wikipedia.org/wiki/Percentile for an explanation of other methods and note the exception for linear interpolation:I was taught to use the formula I showed in my post #32 above.
SD = [ (PD - PMin) / (PMax - PMin) ] (SMax - SMin) + SMin
Where SD = Speed based on your chosen percentile; PD = Your selected percentile (85% in our case); PMin = The cumulative percentage below PD in your distribution table (84% in our case); PMax = The cumulative percentage above PD (97% in our case); SMin = The speed corresponding to PMin (42mph in our case) and SMax = The speed corresponding to PMax (47mph in our case).
You do not simply take the 85th fastest car.
By *definition*, when there are 100 values (as in this problem), the 85th percentile is the 85th largest value when put in rank order. So, yes, you *DO* simply take the 85th fastest car.If there is some integer k for which, then we take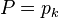 .
.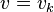
I'm relaxed... just frustrated that for some (e.g. sac) it's as simple as "I'm undoubtedly right" without enough discussion to come to a resolution. And despite all the posts on this topic, it's still very useful because it will clarify a fundamental understanding of percentiles. You previous post was very helpful in understanding our different approaches.Ill, relax dude - this is a friendly discussion.
This, of course, only works if you can make the assumption that, for example, all 18 cars traveling in the 30-34mph interval were traveling at 32mph. Which they probably weren't but, without additional data, I think this is a valid assumption. For all we know, all 18 cars could have been traveling at 30mph, all at 34mph, etc.
This is incorrect. If the vehicle counts were doubled (i.e. total of 200 cars in the sample set), you would still think the 85 percentile speed is 45 mph because of your "bin" theory. This is why the vehicle count versus percentile must be mutually exclusive.By *definition*, when there are 100 values (as in this problem), the 85th percentile is the 85th largest value when put in rank order. So, yes, you *DO* simply take the 85th fastest car.
Now you're just being contrary. Your bin theory does not comply to a normal distribution graph; it would a stepped (layer cake) graph. If you visualize the data as a bell-curve graph, then you have to assign a single value within each bin, like a trend line. You would then use this line to determine your percentile vs. speed graph (i.e. the area under the bell curve at each interval divided by the total number in the sample set).According to DISTRIBUTION OF VEHICLE SPEEDS AND TRAVEL TIMES by DONALD S. BERRY AND DANIEL M. BELMONT of UNIVERSITY OF CALIFORNIA:
"The speeds of vehicles past a point on a highway tend to have a roughly normal distribution except when traffic volume exceeds the practical capacity of the highway."
The data bins certainly look normally distributed to me.
C'mon...Really? Are you going to die on the sword for this one?Major Highway said:Sometimes the accepted method isn't exactly correct, but oh well, I concede.
















